Fault Tolerance Explored: Navigating Systems Resilience, Security, and Best Practices
Systems that are durable and dependable are more important than ever in a world where technology is a part of every aspect of our lives. System failures may have disastrous results, putting money at risk, jeopardizing security, and even putting lives in danger. Fault-tolerant systems come into play here, providing a potent means of reducing the risks connected to system breakdowns. However, what is fault tolerance precisely, and how does it operate? We will cover the following topics related to fault tolerance in this article:
- What is fault tolerance?
- Why are Fault-Tolerant systems indispensable?
- How does fault tolerance Work?
- What are the components of a Fault-Tolerant system?
- What are the Fault tolerance techniques?
- What are the advantages and limitations of Fault tolerance Systems?
- What are the best practices for configuring Fault tolerance?
- What are the differences between software and hardware fault tolerance systems?
- What is the relationship between Fault Tolerance and Cybersecurity?
- What is the relationship between Fault Tolerance and Fault Isolation?
- What are the differences between Fault Tolerance and Resilience?
- What are the differences between fault Tolerance and Disaster Recovery?
- What are the differences between Fault Tolerance and High Availability?
What is Fault Tolerance?
The capacity of a system to continue operating even when one or more of its components malfunction is known as fault tolerance. Potential service outages brought on by software or logical problems are resolved by fault tolerance. The intention is to stop catastrophic failure before it starts, which might come from a single point of failure.
Systems that are fault-tolerant are made to recover from repeated failures. When a component of the motherboard, power supply, memory cards, input/output (I/O) subsystem, central processor unit, or network fails, these systems immediately identify it. Once the breakdown point has been located, a backup part or process takes over without causing any service interruptions.
Businesses must buy a backup uninterruptible power supply and an inventory of formatted computer equipment to provide fault tolerance. By concentrating on uptime and downtime-related problems, the objective is to avoid the failure of important systems and networks.
Software, hardware integrated into hardware, or a mix of the two can offer fault tolerance.
The operating system (OS) in a software implementation offers an interface that enables a programmer to checkpoint important data at predefined points in a transaction. The fault-tolerant capabilities of the machine do not need to be known by the programmer in a hardware implementation.
Hardware fault tolerance is accomplished by duplicating every hardware part. The disks are mirrored. The outputs of several processors are combined and checked for accuracy by comparing them. When an abnormality happens, the equipment keeps working normally until the defective part is identified and removed from service.
Why are Fault-Tolerant Systems Indispensable?
Consider a situation in which a vital system, such as an air traffic control system or a nuclear power plant, malfunctions. The ramifications may be disastrous, possibly resulting in fatalities and significant property damage. This is where fault-tolerant systems come into play; they provide an essential layer of defense that guarantees these intricate systems will continue to function even in the event of a breakdown. This section will look at actual cases that show how powerful and successful fault-tolerant systems can be when they come to the rescue.
Aviation industry: The safety and dependability of aircraft systems are critical when it comes to air travel. The efficient operation of several flight-critical systems is dependent on fault-tolerant systems. For example, fault-tolerant design is incorporated into modern airplanes using Fly-By-Wire (FBW) technology. The system can effortlessly transfer to an alternate control channel in the event that one of the redundant channels fails, ensuring the pilot keeps control of the aircraft. This redundancy has often shown itself to be a life-saving feature, enabling pilots to safely land aircraft even when there are system failures.
Space Exploration: Traveling into space is a difficult and dangerous undertaking. Fault-tolerant design concepts are used in spacecraft systems to reduce the risks associated with failures. The Apollo Guidance Computer (AGC), which was utilized throughout the Apollo lunar missions, is one such instance. Because of its fault-tolerant architecture, the AGC can continue to operate even in the event of hardware malfunctions, such as radiation-induced memory problems. When the AGC experienced many program alarms during the Apollo 11 mission, this capacity was put to the test. But the system recovered and finished the mission successfully because of its fault-tolerant architecture, making the historic moon landing possible.
Financial Systems: Fault-tolerant systems are necessary to preserve the integrity of the financial infrastructure in the world of finance, where transactions take place quickly and include large sums of money. For example, fault-tolerant systems are essential to the continued operation of stock markets. These systems are made to effortlessly transition to redundant components in the case of a breakdown, such as a hardware issue or software bug, reducing interruptions and averting financial losses. These systems' fault-tolerant design has been shown to be essential for preventing market crashes and maintaining the stability of the financial system.
Power Grids: Modern society depends on a steady supply of electricity, and fault-tolerant technologies are essential to maintaining power grid stability. The grid's numerous components are designed with redundancy, which enables automated rerouting of electricity in the case of malfunctions or outages. This guarantees that customers will always get electricity, even in the event that some grid segments have issues. When equipment malfunctions or natural calamities strike, fault-tolerant power grid systems come to the rescue, averting extensive blackouts and lessening the toll on human lives.
Internet Infrastructure: Fault-tolerant systems form the backbone of the Internet, which has grown to be an essential component of our everyday life. To guarantee constant connectivity and data availability, fault-tolerant design concepts are essential in everything from data centers to network routing protocols. For instance, fault-tolerant systems are used by material Delivery Networks (CDNs) to distribute and cache material across
How Does Fault Tolerance Work?
Making sure there isn't a single point of failure in a system is the simplest way to include fault tolerance. This necessitates that there be no one component that could bring the system to a complete halt if it ceased functioning as intended.
The power supply unit (PSU), which receives the primary alternating current (AC) source and transforms it into direct current (DC) of various voltages to power various components, is a typical single point of failure in a conventional system. All the parts that the PSU powers will inevitably fail as well, which will usually result in the catastrophic collapse of the entire system.
Either of these two models is commonly used to describe fault tolerance:
- Regular operation: In some situations, a fault-tolerant system may experience a fault and still operate normally, with no alterations to throughput, reaction time, or any other performance measure.
- Graceful deterioration: Certain errors will cause "graceful degradation" in performance in other fault-tolerant systems. That is to say, the degree of a problem will determine how much of an influence it has on the system's performance. Therefore, a minor error won't have a big effect or maybe bring down the system as a whole. When a system is extremely fault tolerant, it can withstand one or more serious errors without stopping operation.
What are the Components of a Fault-Tolerant System?
In today's technologically advanced world, fault tolerance has become a critical notion. It refers to a system's capacity to continue operating even when errors or failures occur. Knowing the essential elements of fault-tolerant systems is essential if we are to create systems that are not only flawless but also robust in the face of difficulty. This section explores the details of these parts, providing insight into the workings behind the scenes that enable fault-tolerant systems.
- Redundancy: The Foundation of Tolerance for Faults: A key component of fault tolerance is redundancy. It entails tripling or doubling essential system parts so that the system can keep working even if one of them fails. Consider the dual-redundant flight control systems seen in airplanes. Passenger safety is ensured by the flawless transfer of power across systems in the event of a malfunction.
- Error Identification and Fixing: In fault-tolerant systems, error detection and repair procedures are essential. They are intended to detect and, if feasible, fix problems in data storage or transfer. Computers' ECC (Error-Correcting Code) memory is a well-known example; it ensures data integrity by detecting and correcting single-bit mistakes.
- Failover Systems: When a primary system fails, failover systems are meant to automatically move to a backup system. Think about web servers that split up traffic using load balancers. The load balancer transfers traffic to a different server in the event that one server has problems, guaranteeing continuous service.
- Distinguishing Fault Domains: Fault-tolerant systems frequently use isolation strategies to stop problems from harming the system as a whole. Hypervisors and other virtualization technologies generate separate virtual machines (VMs) that isolate and contain faults inside them, therefore protecting the stability of the entire system.
- Predictive maintenance and real-time monitoring: To ensure fault tolerance, the health of the system must be continuously monitored. Predictive maintenance systems are able to identify possible problems before they become serious ones by evaluating performance parameters. Predictive maintenance, which foresees component failures and proactively arranges repairs, is a typical example in industrial machinery.
- Replication in Distributed Systems: Replication and distributed systems are essential to fault tolerance. Multiple servers or sites duplicate data and services. Distributed replication is a technique used by cloud storage providers such as Dropbox to guarantee data availability in the event of a data center outage.
- Graceful Degregation: While certain flaws are unavoidable, they can be controlled. A technique known as "graceful degradation" enables a system to continue operating at a diminished capacity in the event of a breakdown. When referring to online services, this might entail turning off elements that aren't absolutely necessary in order to keep the primary features working.
- Human communication and guidance for making decisions: A crucial component of fault-tolerant systems is the human element. In order to assist human operators in making correctional decisions, systems frequently offer real-time notifications and decision help. Consider air traffic control systems that provide emergency management guidance.
- Examination and Modeling: To ensure that a system is fault-tolerant, extensive testing and simulation are essential. The system's ability to react to unforeseen occurrences may be improved with the use of stress testing, fault injection, and the modeling of complex failure scenarios.
These elements, either separately or in combination, serve as the fundamental building blocks for fault tolerance, enabling systems to absorb errors graciously and continue to provide uninterrupted service. By accepting these components, we set out to create systems that not only aim for excellence but also strengthen against flaws, showcasing the amazing potential of fault-tolerant technology.
What are the Fault Tolerance Techniques?
The ability of a system to function properly even when system failures occur is known as fault-tolerance. Even with so many testing procedures completed, a system failure is still possible. It is practically impossible to make a system completely fault-free. Systems are therefore made to function correctly and provide accurate results even in the event of mistakes, availability, or failure.
The two main parts of every system are the software and the hardware. Either of these might have a flaw. Therefore, fault-tolerance in hardware and software is addressed differently.
What are the Techniques for Hardware Fault-Tolerance?
Creating fault-tolerance in hardware is easier than in software. Techniques for fault-tolerance enable the hardware to function correctly and produce accurate results even when a malfunction arises in the hardware component of the system. Hardware fault tolerance is essentially achieved using two methods:
-
BIST: Build in Self Test, or BIST, is an acronym. The BIST approach to hardware fault-tolerance involves the system repeatedly testing itself after a certain amount of time. The system replaces the malfunctioning component with a redundant one when it detects a failure. The system essentially reconfigures itself when a failure occurs.
-
TMR: Triple Modular Redundancy, or TMR for short. Three redundant copies of essential components are created and executed simultaneously. The majority outcome is chosen once all redundant copies have been voted on. One malfunction at a time can be tolerated by it.
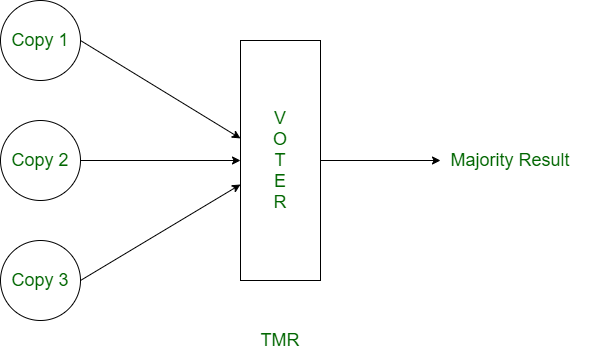
Figure 1. Triple Modular Redundancy
What are the Software Fault-Tolerance Methods?
Software Fault-Tolerance methods are employed to make the program dependable even in the event of failure and fault incidence. Software fault tolerance requires the application of three strategies. The first two methods are widely used and are essentially adaptations of hardware fault-tolerance methods.
-
N-version programming: N people or groups of developers work together to create N software versions. N-version programming is a hardware fault-tolerance approach that is similar to TMR. When using N-version programming, redundant copies are all executed simultaneously, yielding unique results for each processing. The main goal of n-version programming is to catch all faults only when the program is being developed.
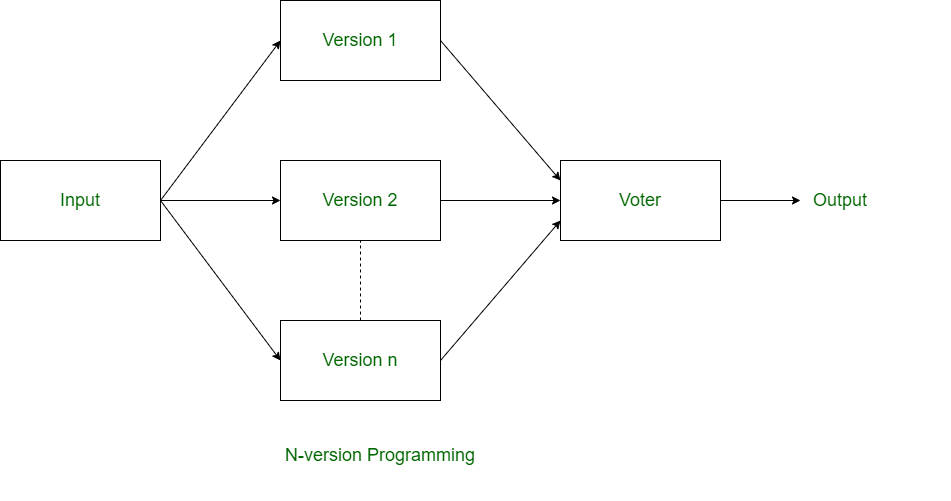
Figure 2. N-version programming
-
Recovery Blocks: The recovery block approach is similar to n-version programming, but it generates redundant copies only through the use of distinct algorithms. The superfluous copies in the recovery block are executed one at a time rather than all at once. The recovery block strategy is only appropriate in situations where the task computation time exceeds the task deadlines.
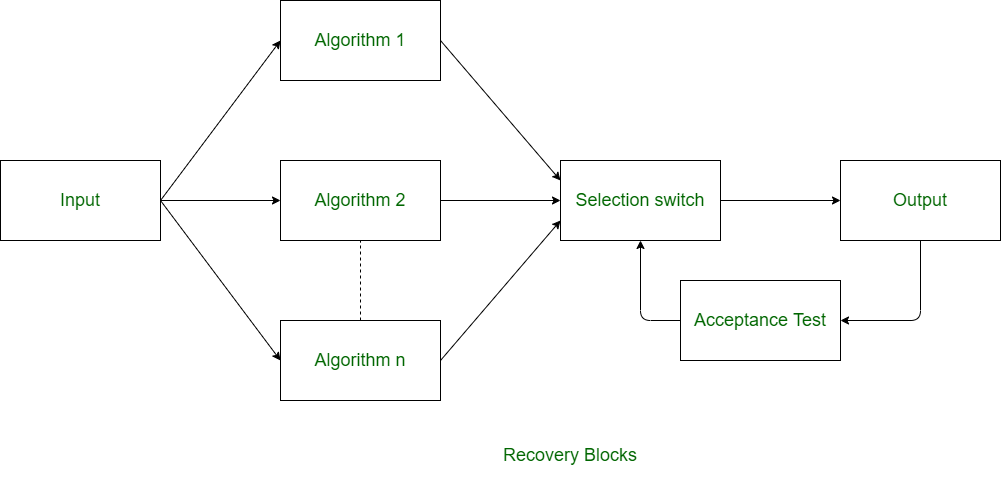
Figure 3. Recovery Blocks
-
Check-pointing and Rollback Recovery: This software fault-tolerance approach differs from the previous two in that it uses check-pointing and rollback recovery. With this method, every time we do a computation, the system is tested. In general, this strategy is helpful in cases of data corruption or processing failure.
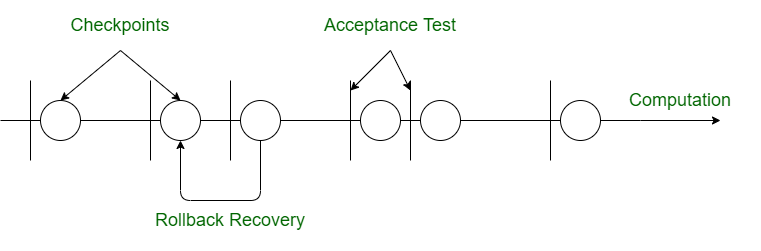
Figure 4. Check-pointing and Rollback Recovery
What are the Advantages of Fault Tolerance Systems?
Fault-tolerant systems provide several, wide-ranging advantages. First off, by lessening the effect of failures, they improve system dependability. A fault-tolerant system may smoothly transition to backup resources thanks to redundant components, guaranteeing continuous operation. This is especially important in sectors where system failures can have serious repercussions, like healthcare, aviation, or finance.
Fault-tolerant systems increase the availability of the system. These solutions raise the overall uptime of vital services by decreasing the downtime brought on by malfunctions. For example, in an e-commerce platform, a fault-tolerant system makes sure that the website keeps working even in the event of a server failure, enabling users to keep making purchases without any interruptions.
What are the Limitations of Fault Tolerance Systems?
Organizations must take on the difficult and demanding process of implementing fault-tolerant systems in order to guarantee the dependability and availability of their vital systems. Although fault tolerance appears simple on the surface, there are really several obstacles and constraints that need to be addressed before such systems can be put into practice. This section will examine some of the major obstacles and constraints that businesses have when putting fault-tolerant systems in place. It will offer views from several angles to help clarify the nuances involved.
- Complexity of Design: The complexity of fault-tolerant systems' designs is one of the main implementation issues. It is important to carefully examine a number of variables when building a system that can endure failures and continue to function normally, including redundancy, error detection and correction systems, and failover procedures. The larger the system's size and scope expand, the more complicated it becomes. Ensuring fault tolerance, for instance, becomes significantly more difficult in distributed systems that span several data centers in various geographical locations because of things like network latency and synchronization.
- Cost and Resources: Putting fault-tolerant systems into place frequently necessitates large expenditures in both human and financial capital. Fault detection measures, redundancy, and backup systems all need extra hardware, software, and infrastructure, which can add up to significant expenditures. To further increase the need for resources, these systems need to be managed and maintained by qualified individuals with fault tolerance experience. Fault-tolerant system implementation and maintenance may be especially difficult for small businesses with tight resources and staffing levels.
- Impact on Performance: Although fault-tolerant systems are made to continue operating even in the event of a breakdown, they may have an adverse effect on the system's overall performance. Redundancy, error detection, and failover systems come with added overhead that might cause throughput to drop and latency to rise. To satisfy the unique needs of the system, a careful trade-off between fault tolerance and performance must be made. For example, the performance effect of fault tolerance methods needs to be reduced to enable optimal execution speed in high-frequency trading systems, where milliseconds count.
- Software Complexity: To identify and recover from faults, fault-tolerant systems frequently rely significantly on sophisticated software algorithms and protocols. Such software is difficult to develop and maintain because it necessitates a thorough grasp of the system architecture in addition to the capacity to foresee and manage a variety of failure scenarios. Furthermore, in a fault-tolerant system, the interplay among various software components may present novel failure modes and escalate the intricacy of debugging and troubleshooting. Complex distributed consensus algorithms like Paxos or Raft, for instance, are needed to provide consistency and stability in distributed database systems in the face of network failures and partitions.
- Scalability: Another issue that businesses run into when putting fault-tolerant systems in place is scalability. Even though a fault-tolerant system could function effectively in a small-scale setting, expanding it to accommodate rising load levels and expanding user bases might be challenging. The number of components, relationships, and failure possibilities in a system increases with its size, making fault tolerance at scale more difficult to achieve. For example, a social media network that sees exponential increases in user activity has to modify and enhance its fault-tolerant design on a constant basis to meet the growing demands.
What are the Best Practices for Configuring Fault Tolerance?
In today's technologically advanced environment, fault-tolerant system design and implementation are essential. It is crucial to put procedures in place to guarantee business continuity and lessen the effect of errors, given the growing reliance on sophisticated systems and their potential for breakdowns and interruptions. We will examine the best practices for developing and putting into practice fault-tolerant systems in this area. We will highlight various viewpoints and provide comprehensive information to assist you in creating strong, resilient systems.
-
Determine and comprehend possible points of failure: Finding potential points of failure is the first stage in creating a fault-tolerant system. A deep comprehension of the relationships, components, and system architecture is necessary for this. Through a comprehensive analysis of the system's hardware, software, and network, you may pinpoint areas of weakness and single points of failure that require attention. For instance, the database server could be an essential part of a web application. You could find that a single database server can develop into a bottleneck or a possible point of failure by looking at the system architecture. In this situation, fault tolerance may be achieved by utilizing a distributed database system or performing database replication, which ensures data availability and redundancy.
-
Redundancy is essential: An important component of fault-tolerant architecture is redundancy. One way to make sure that a single component failure doesn't bring down the entire system is to duplicate important components or implement backup systems. There are several ways to establish redundancy, including in the network, software, and hardware. In a server cluster, for example, having many servers operating in parallel with load balancing guarantees that the others can easily take over the burden in the event of a server failure. Similar to this, you can reduce single points of failure and boost system availability by utilizing redundant power supplies, network switches, and storage devices.
-
Put in place procedures for fault detection and isolation: Failure to do so can result in cascade failures, which can be avoided by detecting errors as soon as they arise. Numerous strategies, including automatic failover systems, health checks, and monitoring, can be used to accomplish this. One way to find abnormalities and possible problems is to use monitoring tools that track system health data continually. Prior to problems affecting the system, you may take proactive measures to resolve them by configuring warnings and automatic reactions. Furthermore, by employing automatic failover techniques like load balancers or clustering, the system may immediately, without any downtime, transition to an alternative in the event of a component failure.
-
Test and validate fault-tolerance measures: Thorough testing and validation are necessary when designing and putting into practice fault-tolerant systems. It is important to run through several failure scenarios and make sure the system operates as it should in diverse settings. For example, doing stress tests in which the system is purposefully overloaded to observe how it manages the additional load can assist in locating any bottlenecks and vulnerabilities. Additionally, the efficacy of fault-tolerance mechanisms may be confirmed by running failover tests to mimic component failures and gauge the system's reaction time.
-
Update and maintain the system frequently: In order for fault-tolerant systems to continue working properly, regular maintenance and upgrades are necessary. To fix vulnerabilities and guarantee peak performance, software, firmware, and security measures must be patched and updated on a regular basis. For instance, maintaining system stability and reducing any security concerns may be achieved by routinely upgrading the operating system and its software components. Routine maintenance procedures, such as component replacements and hardware checks, can also avert possible breakdowns.
What are the Differences Between Software and Hardware Fault Tolerance Systems?
In order to offer service in compliance with the specification, software must be able to recognize and recover from faults that may arise or have already occurred in the hardware or software of the system in which it is operating. On the other hand, the capacity of a component or subsystem to carry out the necessary safety instrumented function in the presence of one or more harmful hardware defects is known as hardware fault tolerance.
What is the Relationship Between Fault Tolerance and Cybersecurity?
Because fault-tolerant design keeps your systems up and guarantees their proper architecture, it helps avoid security breaches. An attacker may quickly knock a carelessly constructed system down, costing your company money, clients, and confidence. For instance, every firewall that is not fault-tolerant puts your website and business at risk for security issues.
What is the Relationship Between Fault Tolerance and Fault isolation?
Consider yourself driving a car when all of a sudden one of the tires blows out. How do you proceed? Most likely, you stop by the side of the road, fix the flat tire, and carry on with your travels. Similar incidents might occur in the realm of technology; thus, we need to find solutions to maintain the functionality of our systems. Fault isolation and fault tolerance are relevant in this situation. Let's explain these ideas in plain language.
For technology, fault tolerance is akin to having a backup plan. Fault tolerance is having backup parts or systems in place to keep things going in case something goes wrong, just like you would have a spare tire in your automobile.
Imagine yourself enjoying your preferred online video game when, all of a sudden, your internet connection becomes a little erratic. The game may run well on a fault-tolerant system, as it's built to withstand sporadic internet outages. It's similar to having a buddy intervene to continue the game while you attempt to repair your internet connection.
Yes, there are flaws in technology. Things break or go wrong from time to time. It can be a network issue, a software bug, or a hardware issue. These problems may bring a system to a complete stop if there is no fault tolerance.
We simply cannot afford downtime in vital systems like airline controls, stock markets, or hospitals. Fault tolerance means ensuring that there is a backup system ready to take over in the event that a component fails. It functions similarly to an airplane's backup engine, allowing the aircraft to continue flying safely in the event that one engine fails.
Being a detective when anything goes wrong in your system is similar to fault isolation. It entails identifying the precise cause of the issue and preventing it from damaging the system as a whole.
Let's say the TV remote control breaks. You might try opening the remote to locate the loose battery connection and correct it, rather than throwing out the entire TV. That's the definition of fault isolation: locating and containing the issue.
We don't want a little fault that occasionally causes a system to go berserk and spread like wildfire. By preventing a fault in one area of the system from crashing the entire thing, fault isolation is ensured.
Consider a mall for shopping. The last thing you want is for the mall to turn into a sauna if the air conditioning in one store malfunctions. The air conditioning system in the mall is set up to limit the problem to one particular store, keeping the remainder of the facility cozy and cool.
In summary, fault isolation and fault tolerance act as technological safety nets. They make sure that our systems continue to function properly even in the event of an error. These ideas guide us through the uncertain world of technology, keeping our lives and companies running smoothly and preventing big setbacks, whether it's a backup plan or a detective's probe. Remember that fault tolerance and fault isolation will come to your rescue the next time something goes wrong with your computer or vehicle!
What are the Differences Between Fault Tolerance and Resilience?
Resilency and fault tolerance are two different things. Although these two names are occasionally used synonymously, they are not the same.
The capacity of a system to endure (tolerate) a defect, for example, a server crash, a network partition, etc., is known as fault tolerance. Performance as a whole could temporarily decline, but system functionalities remain unaffected. This problem can be resolved by mechanisms like replicated state machines and checkpoint/restore. Typically, the systems are capable of self-identifying errors and performing failovers. The service remains operational even if one of the N microservice instances behind a reverse proxy such as nginx fails. Nevertheless, throughput will decline. The service is hence fault-tolerant.
The system's resilience is a gauge of its capacity to bounce back from setbacks. Because Kubernetes automatically maintains the precise number of pods in a replica set, if we perform the example above on Kubernetes, the instance that failed will be immediately brought back up (it might not be the same instance). Therefore, in addition to being robust and fault-tolerant, the circuit breaker design is frequently utilized in microservice architecture to handle resilience issues by allowing the system some recovery time. Any distributed storage system, including Hadoop, will automatically generate the number of under-replicated copies if the number of replicas falls below the replication factor.
It is possible for a system to be robust but not fault-tolerant. For instance, in the first example, what would happen if you had to manually open a second instance?
What are the Differences Between Fault Tolerance and Disaster Recovery?
The capacity to bounce back from setbacks is essential for any system, including Operations Manager, to operate well. Fault tolerance and disaster recovery are essentially distinct ideas, despite their close relationship.
Operating even in the case of a breakdown is known as fault tolerance. This guarantees that service interruptions won't occur from malfunctions. The activation durations of fault-tolerance methods, including load-balanced components or clustering, are usually measured in minutes or seconds. In addition to being highly expensive, these processes sometimes include redundant hardware. However, disaster recovery refers to the capacity to resume activities following a service interruption.
What are the Differences Between Fault Tolerance and High Availability?
Ensuring business continuity through highly available computer systems and networks is directly linked to fault tolerance. In fault-tolerant settings, a service interruption is immediately followed by a service restoration. An environment with high availability aims for 99.999% operational service.
To ensure the system-wide sharing of vital data and resources, groups of independent servers are loosely connected together in a high-availability cluster. The clusters keep an eye on each other's well-being and offer fault recovery to guarantee that applications are always accessible. On the other hand, a fault-tolerant cluster is made up of several physical systems that share one operating system copy. The other systems carry out the software orders that are issued by one system.
Cost is the trade-off between high availability and fault tolerance. The additional hardware required for integrated fault tolerance drives up the cost of the system.